安居客数据采集
安居客数据采集
背景
我有一个中介朋友,他找到我想要抓取安居客网站上的二手房数据。
哈哈,当然忙不白帮,他还意思意思了下。
调查
我们先来到安居客的网站观察一下数据获取方式。
看到默认给我们导航到了北京这个城市,可以类推它应该是按城市、区域、街道划分的,接下来我们将一一寻找这些数据来源。
城市数据源
把鼠标移到北京下可以看到更多城市的链接,可以看到有更多城市的链接。
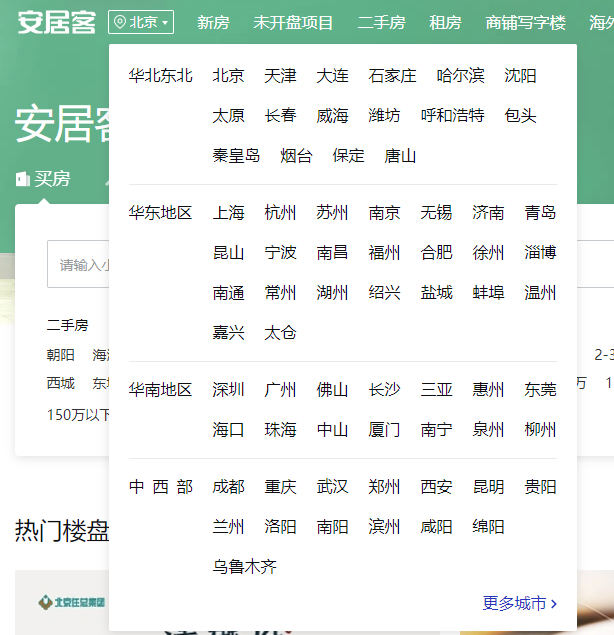
点击链接,就可以看到安居客的所有城市分类:
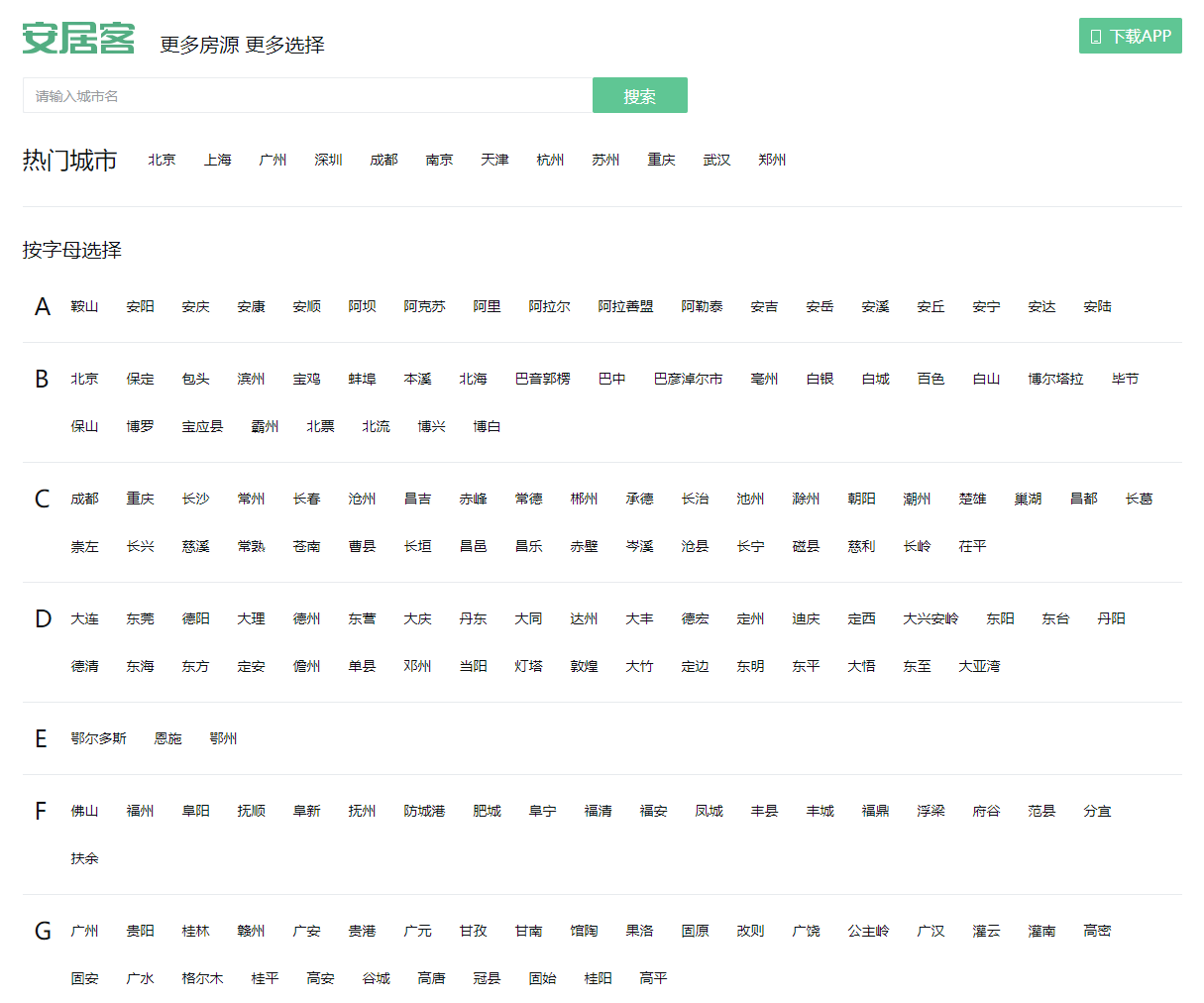
我们接下来分析这一部分的数据是如何渲染到页面上的,即确定是后端渲染还是前端渲染。
先查看网页源代码(快捷键Ctrl+U),浏览器会打开原始的HTML内容没有JavaScript影响,我们可以通过这个来确定。
再获取数据特征值,用特征值去检索有没有出现在网页源代码中。
特征值如何获取?可以取一个标签的完整内容来当特征值,例如在鞍山这个超链接上右键选择检查(其他浏览器上或许有其他叫法,这里以chrome为准,可以使用快捷键Ctrl+Shift+C)来获取a标签的完整HTML代码。
用<a href="https://anshan.anjuke.com?from=AJK_Web_City">鞍山</a>去网页源代码页中检索不到,顾缩小范围搜索鞍山这两个字,发现了在源代码页中是有完整数据结构的,搜索不到是因为少了个/这里猜测是chrome把这个斜杠优化掉了。
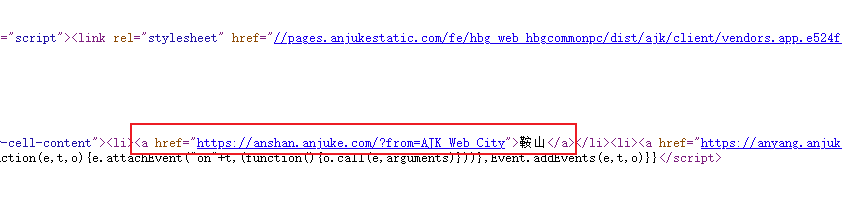
现在可以确定该页面的数据是后端渲染的,我们可以直接请求https://www.anjuke.com/sy-city.html再解析一下HTML即可获取我们所需要的全部城市数据。
城区数据源
上一节中拿到了每个城市的链接,这里直接请求一个链接。
看到页面中还包含有该城市所有的城区分类,我们随便点一个进去再看看。
这里看起来可以得到某个城市的所有区域数据,但别急点进去再看一下。
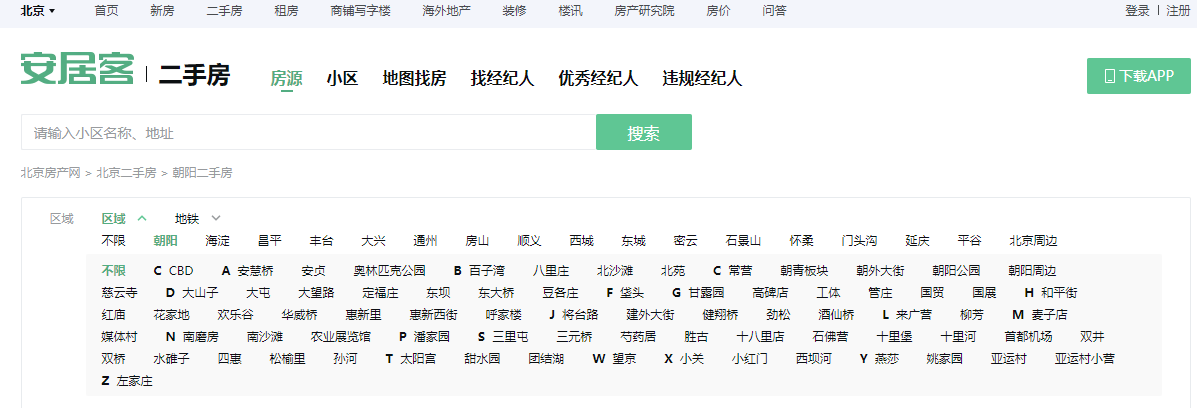
在这里我们找到了一个城市下二手房对应的更详细的分类,这里先看下这一部分的数据是怎么渲染到页面上的
用特征值去网页源代码处搜索,如果搜索得到,那就说明数据不是JavaScript渲染的,就不需要考虑找接口、JavaScript分析了。
所幸,如下图所示,在网页源代码中找到了特征值。

在https://beijing.anjuke.com/sale/页面上,我们可以得到城市的所有区域信息,该页面上还出现了房源信息。
二手房数据源
在https://beijing.anjuke.com/sale/页面上就展示了房源信息,我们需要从该页面上获取详情链接与翻页规则。
详情链接
还是上面提到的方法,要先确认数据源是前端渲染的还是后端渲染的。经过排查,是后端直接渲染的,我们可以直接请求再解析HTML即可。

翻页规则
点击下一页观察浏览器地址栏的变化,可以看到从https://beijing.anjuke.com/sale/变成了https://beijing.anjuke.com/sale/p2/,这里得知了翻页规则。
反爬
调查完了数据源,接下来就是调查它的反爬了。
从它数据渲染的方式上推断,它很可能会采取访问频率的限制。
我们可以简单测试一下,在有二手房数据源页面疯狂刷新(不是常规的F5而是Ctrl+Shift+R,这样可以不使用缓存强制刷新重新请求),果然很快就触发了验证。
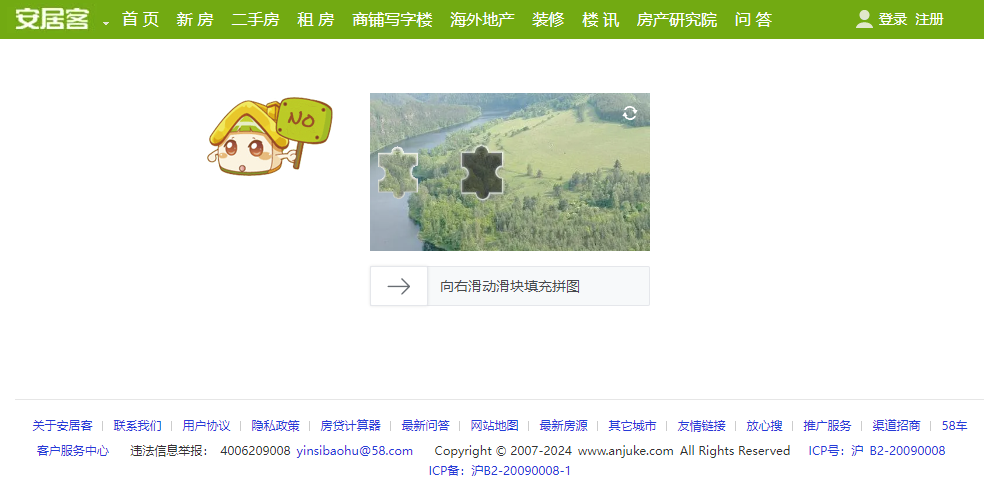
手动解除该验证后,再尝试疯狂刷新页面,于是又触发了新的验证:
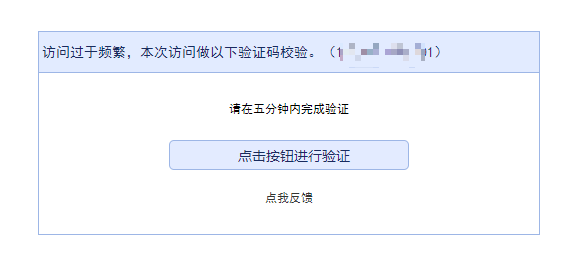
爬虫对抗
既然是采用IP访问频率限制的手段,我们可以根据不同的角度去解决问题。
从IP层面解决
如果我们可以不断的变化自己的IP,那么就不会触发IP访问频率限制了。
我们可以找IP代理商获取IP代理池,每请求几次后再从池中获取新的IP。
如果仅仅是以变换IP作为手段,这几乎是万金油的解法,但成本可不低:
这其中还可能存在不稳定性,因为IP代理商所服务的用户不止你一个,而它的IP总量是有限的,它也会以它的方式去划分IP池。
有可能会获取到上一个用户使用过的IP且该IP已经触发了反爬,这一部分取决于供应商的IP质量还有使用人数越少越好。
从访问频率解决
既然会限制访问频率,那我们五秒请求一次或者十秒请求一次甚至一分钟请求一次,那问题不就解决了?
确实,这样也是一种解法,但速度太慢了。
但也是可以提高速度的,可以用成本换时间。
十秒请求一次,一台机器一分钟请求六次,那如果有十台机器一起跑,那就是一分钟能请求六十次了,相当于一秒请求一次。
当然机器之间的对外IP要各自独立,编码上也从多线程变成了分布式。
从人机验证解决
上面两种解决路线比起这条相对来说算软,突破人机验证需要一定的技术力,得靠硬。
解决人机验证有两种方案,一种是利用浏览器去模拟人工,另一种是JavaScript逆向。
这两种都需要花很长的篇幅以及很高的专业性,我也不是很熟悉,顾一笔带过。
总结
安居客的数据源是比较容易获取的,难点就在于爬虫对抗,这点要考虑自身对于数据获取速度的要求。
爬虫对抗最好是综合各种角度的解决方案进行融合,这样综合性最好的,还需要考虑自身的情况结合进行选择。
编码方面就比较随意了,按自己舒服的来,我是使用了Java编写了爬虫,你也可以使用Python,在这里语言成了工具,哪个顺手用哪个,区别都不是很大。